
Le strategie di crescita inorganiche, come le fusioni e acquisizioni (M&A), fungono da leve strategiche per la crescita, permettendo alle aziende di realizzare sinergie di ricavi e costi o di acquisire rapidamente capacità emergenti che garantiscano un vantaggio competitivo a lungo termine. Oggi, ad esempio, osserviamo grandi organizzazioni che acquisiscono start-up AI più piccole e innovative per accelerare i loro sforzi di trasformazione e ottenere un vantaggio competitivo.
L'integrazione della tecnologia gioca un ruolo cruciale nell'acquisizione di valore da M&A. Uno studio di Deloitte sostiene che l'IT è un motore chiave dei vantaggi dell'integrazione, rappresentando oltre il 50% di tutte le sinergie. Tuttavia, a causa della proliferazione dei silos di dati e delle diverse architetture e ambienti tecnologici, le organizzazioni devono affrontare diverse sfide post-fusione per realizzare i vantaggi dell'integrazione tecnologica.
Questo articolo presenta un framework in cinque fasi per affrontare queste sfide e accelerare l'acquisizione del valore in contesti di M&A. Garantirà che la tua strategia dati post-fusione con Cloudera ti fornisca le funzionalità necessarie per semplificare il processo di integrazione tecnologica.
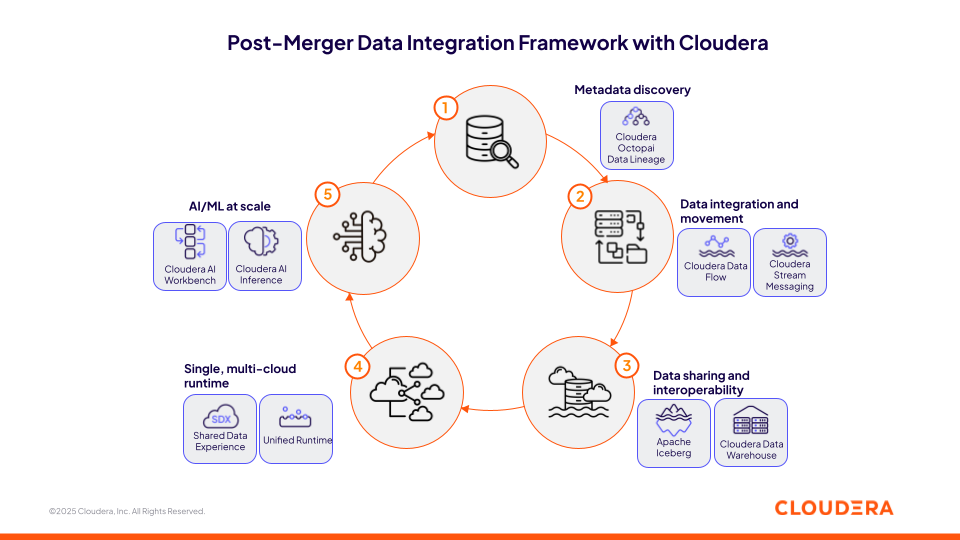
Figura 1: framework di integrazione dei dati post-fusione con Cloudera
1. Accelera l'integrazione post-fusione con Cloudera Octopai Data Lineage
All'inizio dell'integrazione post-fusione, la fase di scoperta dei dati spesso diventa un collo di bottiglia, poiché fonti frammentate e non documentate ritardano gli sforzi critici di analisi e conformità. Cloudera Octopai Data Lineage affronta questa sfida fornendo una soluzione automatizzata di gestione dei metadati basata sull'AI che accelera la scoperta dei dati, il lineage end-to-end e la catalogazione in ambienti ibridi e multi-cloud complessi.
Cloudera Octopai Data Lineage mappa in modo efficace i flussi di dati e colma le lacune dei metadati, fornendo un lineage multidimensionale che monitora origini e trasformazioni per una visibilità completa. Con oltre 60 integrazioni native e connettori universali per sistemi non nativi, Cloudera Octopai Data Lineage semplifica l'onboarding dei dati acquisiti, migliorando così la trasparenza, la qualità e l'affidabilità dei dati.
Ad esempio, negli scenari di fusione bancaria, questa capacità facilita l'identificazione rapida e l'etichettatura di dataset correlati al rischio, garantendo la conformità agli standard normativi come BCBS 239 e riducendo al minimo la necessità di audit manuali estesi o di interventi.
2. Integra diverse fonti di dati con Cloudera Data In Motion
L'integrazione di diverse fonti di dati e l'eliminazione di complesse pipeline ETL personalizzate rappresenta una sfida post-fusione critica. Cloudera offre capacità robuste per l'ingestione, l'elaborazione e la distribuzione dati in batch e in tempo reale tramite Cloudera Data Flow (alimentato da Apache NiFi) e Cloudera Streaming (alimentato da Apache Kafka e Apache Flink).
Con oltre 450 connettori, Cloudera Data Flow offre un'interfaccia visiva drag-and-drop per l'acquisizione di dati da diverse origini di dati eterogenee on premise, nel cloud e all'edge. Inoltre, Cloudera Streaming fornisce un'architettura bus di messaggistica che disaccoppia i sistemi di origine dai sistemi di consumo tra le due entità, eliminando così le integrazioni punto a punto che aggiungono complessità architettonica e costi più elevati.
Durante l'integrazione post-fusione, queste capacità possono accelerare e semplificare significativamente il trasferimento dei dati tra le organizzazioni. Ad esempio, Cloudera Data Flow può essere utilizzato per integrare rapidamente i dati on premise provenienti dai sistemi sorgente legacy dell'azienda acquisita nel data warehouse cloud-native della società madre, accelerando il processo decisionale.
3. Crea un livello di condivisione dati sicuro su Cloudera Open Data Lakehouse con Apache Iceberg
La condivisione dei dati tra entità in fusione è un requisito essenziale per il processo decisionale integrato e per ricavare informazioni. Questo processo può risultare complesso a causa delle diverse tecnologie di analisi esplorativa e di business intelligence, nonché dei vari modelli di sicurezza dei dati utilizzati dai diversi sistemi.
Un approccio di tipo "open data lakehouse" che combina Apache Iceberg, Cloudera Iceberg REST Catalog e Cloudera Shared Data Experience (SDX) consente alle organizzazioni di sviluppare un livello unificato di condivisione dei dati compatibile con vari motori analitici (ad esempio Snowflake, Databricks, AWS EMR, AWS Athena e Salesforce Data Cloud, purché questi motori siano abilitati per Iceberg REST Catalog) e fornisce un modello di sicurezza e governance molto dettagliato per gestire l'accesso a una vasta gamma di utenti, fra cui i nuovi team di data science integrati.
Ad esempio, due organizzazioni sanitarie impegnate nella produzione di farmaci possono sfruttare Cloudera per costruire un data lakehouse conforme a GxP che consolidi gli asset dati delle entità in fusione garantendo al contempo il rispetto dei requisiti normativi.
4. Standardizza le iniziative inter-ambientali su un unico ambiente multi-cloud
I diversi ambienti utilizzati per le attività analitiche nelle due entità che si fondono portano a operazioni duplicate durante tutto il ciclo di vita dei dati, fra cui molteplici pipeline di data engineering per attività comuni come l'inserimento e la standardizzazione.
Cloudera consente alle organizzazioni di standardizzare i dati e le operazioni di AI su un runtime comune in vari ambienti cloud privati e pubblici. Questa capacità deriva dal modello infrastrutturale containerizzato sottostante utilizzato in diversi ambienti, da un meccanismo coerente di autenticazione e autorizzazione degli utenti (Cloudera SDX) e da Cloudera Manager, che funge da unico punto di controllo per gestire i cluster tra diversi ambienti di distribuzione e regioni.
In un contesto post-fusione, questa standardizzazione è trasformativa: le due aziende possono integrare le operazioni del ciclo di vita dei dati in un unico runtime, eliminando strumenti ridondanti e facilitando la condivisione di dati, insight e modelli di AI. Ciò comporta una riduzione dei costi tecnologici e di manodopera per le operazioni sui dati e lo sviluppo di modelli AI/ML, un aumento della produttività dei professionisti, il consolidamento di più strumenti e la riduzione dei silos di dati.
5. Scalare le iniziative di IA ovunque con Cloudera AI
Dopo l'acquisizione o la fusione, la sfida immediata è integrare i diversi strumenti, modelli e data scientist della nuova start-up innovativa acquisita, gestendo al contempo le crescenti esigenze di capacità. Cloudera AI Workbench e AI Inference permettono alle organizzazioni di scalare le iniziative di IA sia on premise che nel cloud attraverso:
Fornitura di una soluzione end-to-end basata su container per l'ingegneria delle funzionalità, la formazione dei modelli, il monitoraggio della sperimentazione e la distribuzione dei modelli.
Agevolazione della condivisione di modelli AI che permette ai data scientist di collaborare tra team diversi
Utilizzo di servizi di accelerazione hardware e software dei partner Cloudera che possono accelerare l'intero ciclo di vita della data science, migliorando le prestazioni di data engineering di 20 volte e le prestazioni di inferenza AI fino a 6 volte
Con Cloudera, l'azienda integrata può ottenere una notevole riduzione dei costi spostando carichi di lavoro persistenti e ad alta intensità di calcolo, come il serving di modelli AI/ML, verso ambienti on premise. E, cosa ancora più importante, può accelerare il time-to-market per le nuove applicazioni AI combinate. Questo permette all'organizzazione di raggiungere rapidamente il "vantaggio competitivo" che cercava fin dall'inizio con la M&A
Fai il passo successivo per garantire un'integrazione di successo dopo la tua prossima fusione e acquisizione
Cloudera può accelerare l'integrazione post-fusione degli asset di dati e delle capacità analitiche tra le due entità che si stanno integrando. La nostra piattaforma offre scalabilità lungo il ciclo di vita dei dati, un modello di distribuzione indipendente dall'infrastruttura e l'interoperabilità del data lakehouse sui servizi di Cloudera e Apache Iceberg. Questa combinazione fornisce un modello architettonico per standardizzare le iniziative e le operazioni sui dati AI/ML, e per fornire un modello di condivisione dei dati utilizzabile sia dai servizi Cloudera che da quelli non Cloudera.
Per programmare una demo o un tour del prodotto, contatta il nostro team.
