Democratizzare i dati per l'AU utilizzando l'interoperabilità tra motori e la collaborazione dei dati senza copie.




Come il catalogo REST di Iceberg di Cloudera abilita le imprese aperte e pronte per l'IA.
L'interoperabilità è da tempo una parola d'ordine, non una capacità su cui le imprese possono contare nella pratica. Invece, i data architect spesso si trovano a mettere insieme sistemi frammentati, i chief data officer affrontano enormi rischi e un vincolo del fornitore dovuto a una governance compartimentata, e i leader della piattaforma sono limitati nel fornire una visione dei dati coerente ai loro team. Che si tratti di fusioni, strategie multi-cloud o partnership esterne, lo schema si ripete: aumento dei costi, innovazione più lenta e capacità limitata di scalare l'AI con sicurezza.
In Cloudera, abbiamo aiutato i nostri clienti a navigare queste sfide: strati di metadati disconnessi, pipeline di dati duplicate e modelli di governance che non riescono a estendersi attraverso gli strumenti, sempre sforzandoci di abilitare imprese aperte e pronte per l'IA che sbloccano l'interoperabilità su larga scala.
Perché l'apertura è importante per l'IA aziendale
Per scalare i carichi di lavoro dell'AI, le organizzazioni hanno bisogno di visibilità e controllo sui dati che li alimentano. L'intelligenza dei metadati svolge un ruolo fondamentale in questa equazione, permettendo alle organizzazioni di comprendere dove vivono i dati, come sono strutturati e come vengono utilizzati tra team e strumenti.
Con standard aperti come Apache Iceberg e l'Iceberg REST Catalog, le aziende ottengono uno strato unificato di metadati che supporta la condivisione dei dati zero-ETL, garantisce la governance e alimenta l'interoperabilità sicura tra motori di analisi e AI. Questa base trasforma infrastrutture frammentate in un'architettura dati connessa e pronta per l'AI, in cui i metadati diventano la chiave per accelerare l'accesso agli insight mantenendo la fiducia.
Aperto, sicuro e semplice: Cloudera Iceberg REST Catalog
Cloudera Iceberg REST Catalog alimenta il nostro open data lakehouse e aiuta le organizzazioni a semplificare l'architettura, ridurre la duplicazione e estendere l'accesso sicuro ai dati ovunque sia necessario.
Agisce come un livello di metadati universale e interoperabile e fornisce un accesso zero-copy alle tabelle Iceberg attraverso strumenti, cloud e team, consentendo agli strumenti open-source e di terze parti di accedere agli stessi dati. Funzionalità e vantaggi includono:
- Aperto e indipendente dai motori: fornisce API basate su standard che supportano strumenti come Athena, Databricks, Redshift e Snowflake, consentendo l'interoperabilità senza il blocco dei fornitori.
- Disaccoppiato by design: astrae i motori di query dai metastore backend, riducendo la complessità e aumentando la portabilità tra gli ambienti
- Accesso ai metadati in tempo reale: supporta interrogazioni di metadati veloci e aggiornate da metastores compatibili con Iceberg, migliorando la visibilità dei dati tra i team.
- Governato e sicuro: estende i controlli di accesso a granularità fine, le autorizzazioni a livello di riga e l'integrazione della gestione dell'accesso basato su identità aziendale (IAM) (come LDAP e OAuth2) a tutti i sistemi collegati, garantendo un'applicazione coerente delle policy su larga scala.
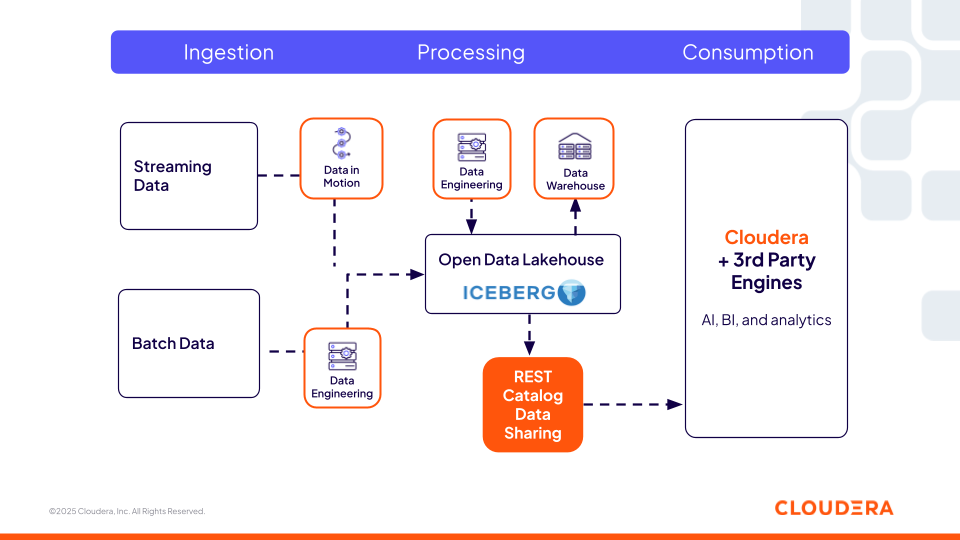
Figura 1. Il catalogo Iceberg REST di Cloudera fornisce uno strato di metadati universale e interoperabile, permettendo a strumenti open source e di terze parti di accedere agli stessi dati.
Casi d'uso reali e impatto del catalogo REST di Iceberg
I seguenti esempi concreti illustrano come le organizzazioni utilizzano Iceberg REST Catalog per semplificare il proprio stack di dati, ridurre il costo totale di proprietà (costo totale di proprietà, TCO) e accelerare il tempo per ottenere valore, il tutto mantenendo i dati dove devono essere.
Insieme, questi esempi dimostrano come l'approccio aperto e interoperabile di Cloudera acceleri i risultati dell'IA, migliori l'efficienza operativa su scala aziendale e permetta sicurezza e conformità.
Condivisione dei dati: scala le applicazioni AI a oltre 3.000 utenti multipiattaforma.
Un produttore di automobili di lusso ha affrontato sfide crescenti nella condivisione sicura dei dati con un partner esterno utilizzando Databricks. I metodi tradizionali si basavano sulla duplicazione dei dati, introducendo costi, complessità e inflessibilità architettonica.
Adottando il catalogo REST di Iceberg, il cliente ha stabilito una condivisione sicura dei dati zero-ETL tra sistemi interni ed esterni. Questo approccio aperto e basato su standard ha consentito loro di scegliere gli strumenti migliori per il lavoro, utilizzando Spark per pipeline di dati complesse e Impala per analisi SQL rapide. Con questa base, l'azienda ha scalato le applicazioni di AI a più di 3.000 utenti, mantenendo la piena governance e il controllo sull'accesso ai dati.
Ottimizzazione del Data Warehouse: riduzione dei costi di spostamento dei dati del 74%
A seguito di un'attività di fusione, una società satellitare globale ha incontrato ostacoli significativi nell'unificare dati frammentati bloccati in sistemi proprietari. Senza uno strato dati coerente e interoperabile, le loro iniziative di AI e analisi sono state lente da scalare e difficili da gestire.
L'architettura open data lakehouse di Cloudera, alimentata dal catalogo Iceberg REST, ha aiutato il cliente a consolidare questi silos e a stabilire una fonte unica di verità per tutti i suoi carichi di lavoro di AI e analisi. Interrogando le tabelle Iceberg gestite direttamente in S3, hanno eliminato la necessità di pipeline di dati ridondanti e di sforzi di ripiattaforma, con una conseguente riduzione del 74% dei costi di spostamento dei dati.
Demo: uno sguardo più da vicino alla condivisione dei dati tramite il Catalogo REST Iceberg di Cloudera.
Questa demo interattiva dà vita al catalogo REST di Iceberg attraverso uno scenario di servizi finanziari. Presso la fictional Parent Bank, diversi team utilizzano i loro strumenti preferiti, come Snowflake e AWS Athena, per accedere in modo sicuro a un'unica fonte governata di dati, il tutto senza un complesso ETL o un costoso movimento di dati.
Per approfondire questa offerta e scoprire come può apportare benefici alla tua organizzazione, esplora queste risorse:
- Visita la nostra pagina prodotto per saperne di più sulla lakehouse open data di Cloudera.
- Leggi il comunicato stampa per l'annuncio completo sulla visione di Cloudera per la condivisione aperta dei dati.