Cloudera Data Engineering
Crea, orchestra e gestisci pipeline di dati di livello enterprise con Apache Spark su Iceberg. Alimenta un'AI scalabile e un'analisi multifunzione dai cloud ai data center.

Panoramica
Lo standard aperto per il data engineering aziendale
Il data engineering consente ai team aziendali di creare, automatizzare e scalare in modo sicuro le pipeline di dati sulle fondamenta di un lakehouse aperto. Potenzia l'analytics multifunzione e l'AI per i dati ovunque.

Unifica i dati strutturati e non strutturati con Apache Spark su Iceberg, orchestrati tramite Airflow, completamente aperto, senza vincoli di fornitore.
Crea, esegui e gestisci pipeline di dati ovunque: sul cloud, nei data center o in ambienti ibridi, con flessibilità containerizzata e governance unificata.
Raggiungi l'efficienza dei costi mediante strumenti di governance finanziaria per l'ottimizzazione delle risorse, inclusa l'osservabilità a livello di carico di lavoro, la scalabilità automatica e la condivisione dati zero-ETL.
CASI D'USO
Crea pipeline di dati end-to-end per accelerare AI e analytics.
-
Crea pipeline scalabili per i dati ovunque
Sposta la portabilità del carico di lavoro, gli standard aperti e la scalabilità sul cloud e on premise.
-
Accelera DataOps con l'orchestrazione
Automatizza i flussi di lavoro, itera le pipeline e semplifica le collaborazioni.
-
Condivisione dati zero-ETL
Garantisci un accesso sicuro e affidabile ai dati, sia internamente che esternamente.
-
Monitora e ottimizza i costi delle pipeline
Riduzione del TCO con osservabilità e calcolo efficiente.
-
Crea pipeline scalabili per i dati ovunque
Sposta la portabilità del carico di lavoro, gli standard aperti e la scalabilità sul cloud e on premise.
-
Accelera DataOps con l'orchestrazione
Automatizza i flussi di lavoro, itera le pipeline e semplifica le collaborazioni.
-
Condivisione dati zero-ETL
Garantisci un accesso sicuro e affidabile ai dati, sia internamente che esternamente.
-
Monitora e ottimizza i costi delle pipeline
Riduzione del TCO con osservabilità e calcolo efficiente.
20%
efficienza migliorata per i team di dati
Aumenta l'efficienza con portabilità, orchestrazione e accesso unificato ai dati da Cloudera on premise.
Esegui Spark, Iceberg e Airflow ovunque, con un'esperienza di data engineering cloud-native.
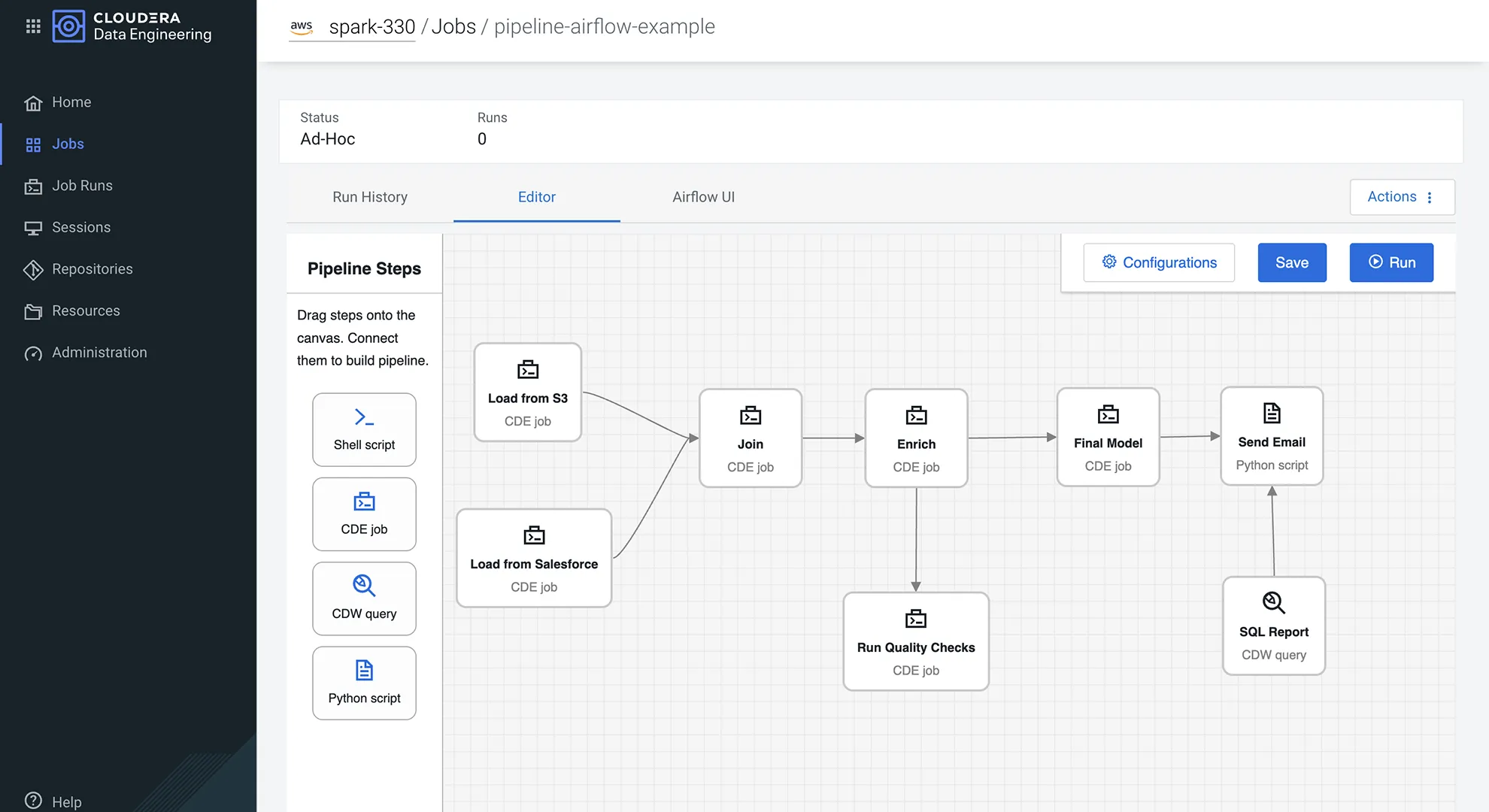
Aumenta la produttività dei professionisti con strumenti intuitivi e sicuri a livello aziendale
Crea, testa e orchestra le pipeline con Sessions e Apache Airflow.

Fornire nuovi dati a pipeline downstream e piattaforme esterne.
Connettiti a motori esterni tramite Iceberg REST Catalog con governance e tracciabilità dei metadati.
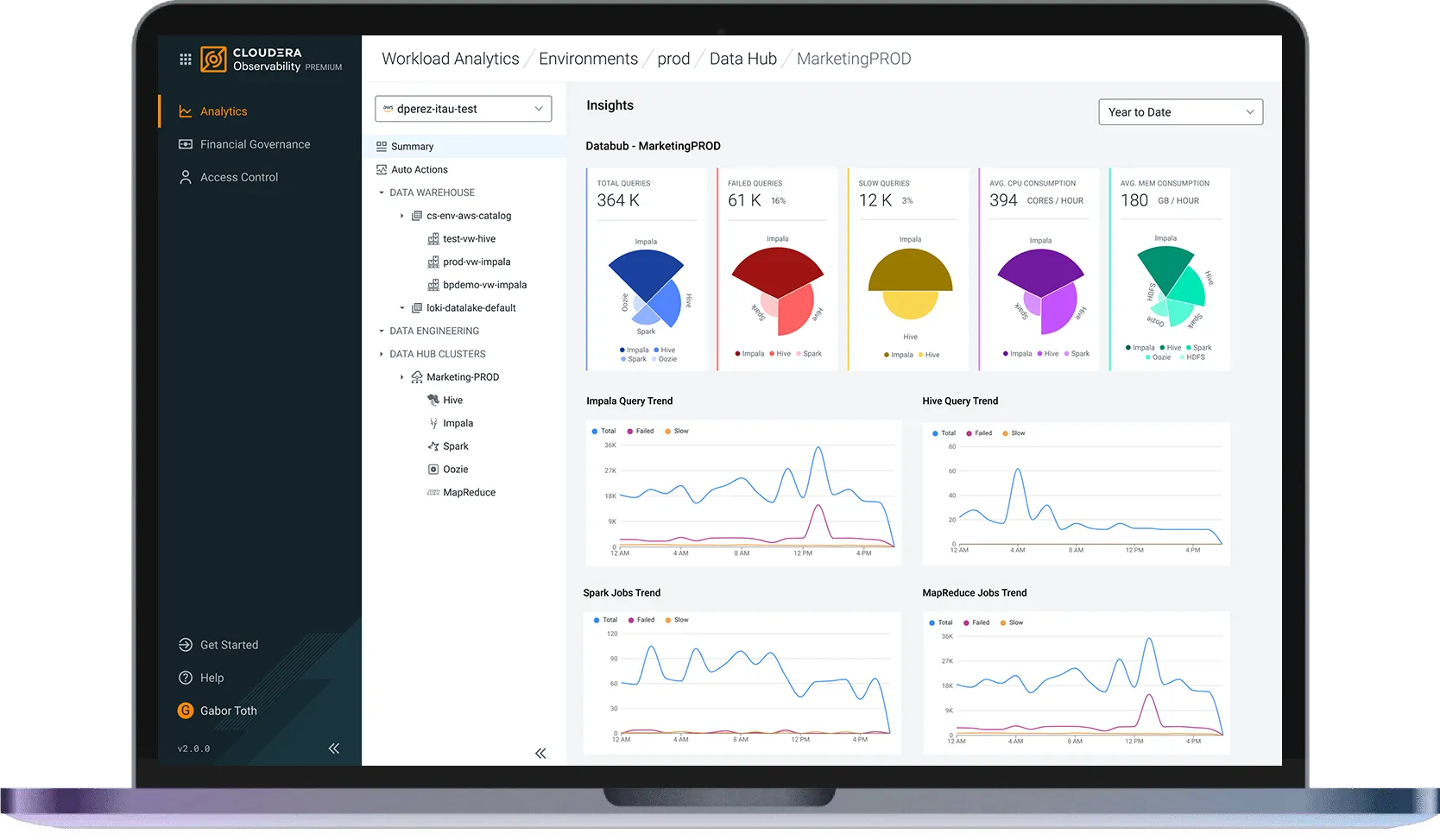
Scala in modo più intelligente con la governance finanziaria a livello di carico di lavoro
Ottimizza i costi con approfondimenti integrati e processori AWS Graviton a basso consumo energetico.
Migrazione ad Apache® Iceberg per principianti
Leggi questa guida dettagliata per migrare i tuoi carichi di lavoro su Apache Iceberg.

Esegui pipeline scalabili e governate con Spark su Iceberg nei container dall'open data lakehouse. Sfrutta la rivoluzione degli schemi di Iceberg, le indagini cronologiche e la condivisione di dati esterni in ambienti on premise o cloud.
Orchestrazione drag-and-drop per flussi di lavoro complessi, semplificando la gestione delle attività, il controllo delle dipendenze e la connettività con strumenti esterni.
Avvia sessioni on-demand per test rapidi e iterazioni. Abilita lo sviluppo remoto e sicuro da qualsiasi IDE, ad esempio VSCode e Jupyter Notebook, grazie a Spark Connect.
Mantieni i dati aggiornati catturando le variazioni a livello di riga dai sistemi sorgente. Automatizza gli aggiornamenti continui per costruire pipeline di dati affidabili.
Monitora le pipeline di dati end-to-end con derivazione e gestione dei metadati integrate grazie alla tecnologia di Cloudera Shared Data Experience (SDX) e Cloudera Data Lineage per ottenere visibilità automatizzata, governance e insight affidabili su ambienti ibridi.
Automatizza i flussi di lavoro della pipeline su qualsiasi servizio con API affidabili, indipendentemente dal fatto che lavori in SQL, Java, Scala o Python. Diagnostica e risolvi rapidamente i problemi di prestazioni con una profilazione visiva in tempo reale, completa di monitoraggio integrato e avvisi per ogni fase del ciclo di vita.
Caratteristiche per tipo di cluster Cloudera Data Engineering
| Core cluster | Cluster multiuso | ||
Infrastruttura |
Cluster di ridimensionamento automatico | ||
| Istanze spot | |||
| Cloudera Shared Data Experience | |||
| Open lakehouse con Iceberg | |||
Spark |
Gestione del ciclo di vita del lavoro | ||
| Monitoraggio centralizzato | |||
| Orchestrazione del flusso di lavoro (Airflow) | |||
| Streaming Spark | |||
Endpoint di sviluppo |
Sessioni interattive | ||
| Connettività IDE esterna | |||
| Connettore JDBC (presto disponibile) | |||
Opzioni di distribuzione di Cloudera Data Engineering
Livello di elaborazione unificato su un data lakehouse aperto e ibrido.
Cloudera su cloud
- Flessibilità multi-cloud: distribuisci sui cloud pubblici con servizi containerizzati e API-first, senza blocchi e completamente interoperabili.
- Esperienza di sviluppo modulare: usa Apache Airflow, Spark gestito, API e IDE, e accelera lo sviluppo con collaborazioni iterative.
- Scalabilità elastica: ridimensiona automaticamente i carichi di lavoro Spark in modo dinamico e ottimizza i costi in base all'utilizzo.
Cloudera on premise
- Controlla la tua distribuzione: distribuisci sui cloud pubblici con servizi containerizzati e API-first, senza blocchi e completamente interoperabili.
- Esperienza pronta per il cloud: ottieni gli stessi servizi modulari e containerizzati del cloud, costruiti per la portabilità ibrida e la scalabilità.
- Pensato per le aziende: sfrutta l'onboarding rapido, l'accesso IDE esterno e i controlli di accesso dettagliati per impostazione predefinita.
CLIENTI
Scelto dai team per trasformare i dati ibridi in impatto aziendale.
 Trasporti
GEODIS
Trasporti
GEODIS
 Servizi finanziari
Nord/LB
Servizi finanziari
Nord/LB
 Manifatturiero e automobilistico
International
Manifatturiero e automobilistico
International
Connettori, integrazioni e partner.
Costruisci pipeline su un ecosistema di dati aperto e interoperabile. Effettua l'integrazione con i principali motori, provider cloud e strumenti nel tuo stack di dati moderno.
Elaborazione dei dati
Data lake e data warehouse
Orchestrazione dei dati
Inserimento in streaming
Motore NoSQL
Data lake e data warehouse
Fornitore di servizi cloud
Fornitore di servizi cloud
Fornitore di servizi cloud
Fornitore di servizi cloud
Orchestrazione dei container
Data warehouse
Fai il passo successivo
Approfondisci i dettagli ed esplora le potenti funzionalità di Cloudera Data Engineering.
Tour del prodotto Data Engineering
Dai un'occhiata più da vicino a Cloudera Engineering con un tour del prodotto.
Documentazione su Data Engineering
Scopri nel dettaglio come iniziare a utilizzare Cloudera Data Engineering.
Esplora altri prodotti
Analizza grandi quantità di dati per migliaia di utenti simultaneamente, senza compromettere velocità, costi o sicurezza.
Prendi decisioni intelligenti con una piattaforma flessibile che elabora qualsiasi dato, ovunque, per fornire analisi fruibili e un'IA affidabile.
Accelera il processo decisionale basato sui dati, dalla ricerca alla produzione, con una piattaforma protetta, scalabile e aperta per l'AI aziendale.
Raccogli e sposta i tuoi dati da qualsiasi fonte a qualsiasi destinazione in modo semplice, sicuro, scalabile ed economico.