Cloudera AI Inference Service
Accelera la fornitura dei modelli per distribuire e scalare applicazioni, agenti e assistenti di AI privata con velocità, sicurezza ed efficienza impareggiabili.

Sviluppo e implementazione dell'AI all'avanguardia con la garanzia di sicurezza di tutte le fasi del ciclo di vita.
Basato sui microservizi NVIDIA NIM, Cloudera AI Inference Service offre prestazioni uniche sul mercato, fornendo un'inferenza fino a 36 volte più veloce sulle GPU NVIDIA e quasi 4 volte il throughput sulle CPU, semplificando la gestione e la governance dell'AI in modo fluido su cloud pubblici e privati.
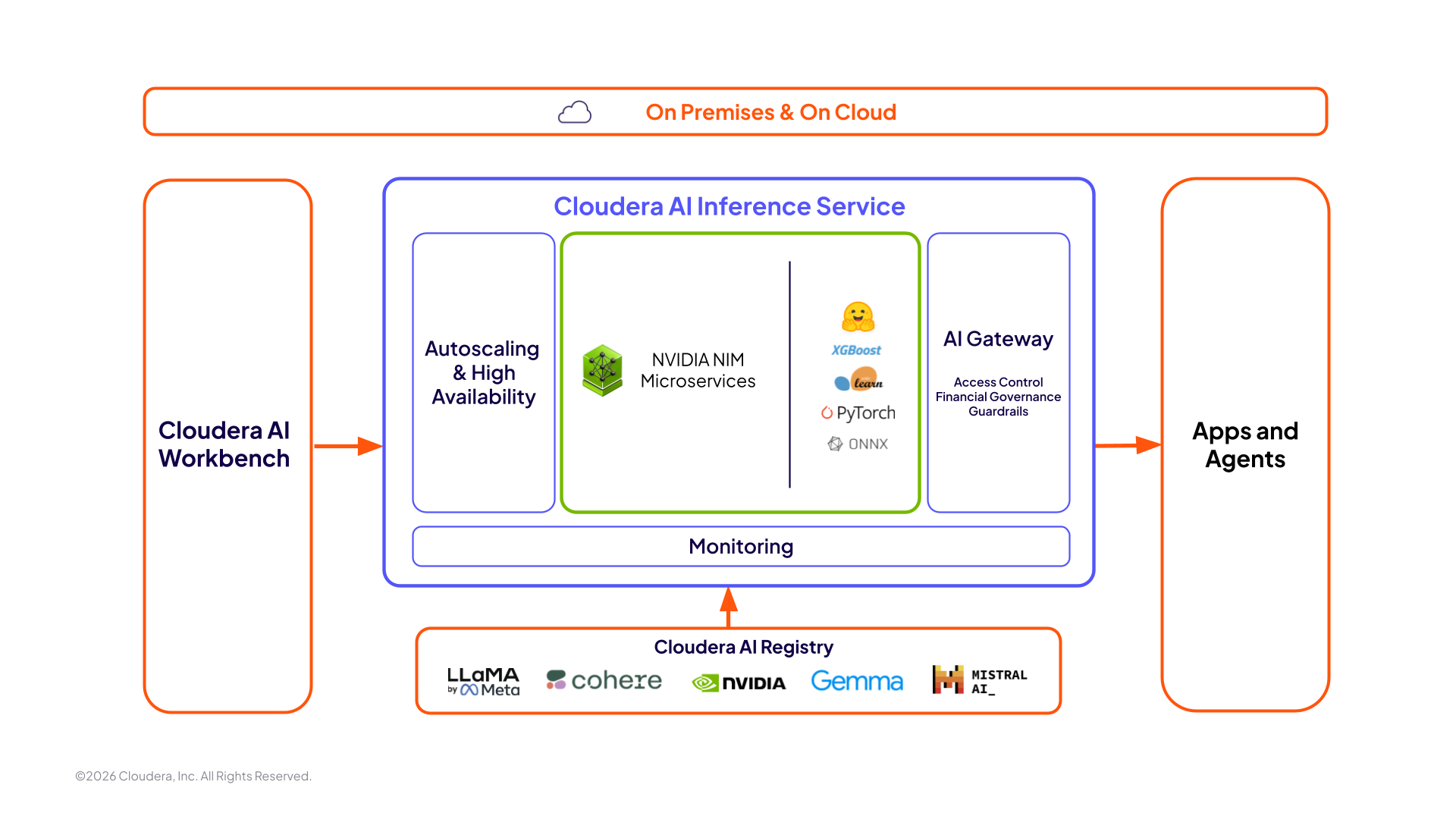
Un unico servizio per tutte le tue esigenze di inferenza AI aziendale
Deployment con un solo clic: porta rapidamente il tuo modello dalla fase di sviluppo alla produzione, indipendentemente dall'ambiente.
Un unico ambiente protetto: ottieni una solida sicurezza end-to-end che copra tutte le fasi del ciclo di vita della tua AI.
Un'unica piattaforma: gestisci senza problemi tutti i tuoi modelli su un'unica piattaforma per tutte le tue esigenze di AI.
Sportello unico per l'assistenza: ricevi supporto unificato da Cloudera per qualsiasi domanda su hardware e software.
Caratteristiche principali di AI Inference Service
Opzioni di distribuzione del servizio di inferenza AI
Esegui carichi di inferenza on premise o nel cloud senza compromettere le prestazioni, la sicurezza o il controllo.
Cloudera su cloud
- Flessibilità multi-cloud: distribuisci su cloud pubblici ed evita i blocchi dell'ecosistema.
- Tempo di valorizzazione più rapido: inizia a fare inferenze senza configurare l'infrastruttura, ideale per sperimentazioni rapide.
- Scalabilità elastica: gestisci il traffico imprevedibile con scalabilità automatica fino a zero e microservizi ottimizzati per GPU.
Cloudera on premise
- Sovranità dei dati: mantieni il controllo completo. Mantieni modelli, prompt e risorse completamente dietro il tuo firewall.
- Pronto per ambienti air-gapped: progettato per ambienti regolamentati come quelli governativi, sanitari e dei servizi finanziari.
- TCO prevedibile e inferiore: elimina le sorprese con prezzi fissi e un TCO inferiore rispetto alle API cloud basate su token.
DEMO
Sperimenta in prima persona l'implementazione fluida dei modelli
Scopri quanto è facile distribuire modelli linguistici di grandi dimensioni con la potenza degli strumenti di Cloudera che consentono di gestire efficacemente applicazioni AI su larga scala.

Integrazione del registro dei modelli:
accedi, archivia, crea versioni e gestisci i modelli senza problemi tramite il repository centralizzato Cloudera AI Registry.
Configurazione e distribuzione semplici: distribuisci i modelli negli ambienti cloud, configura gli endpoint e regola l'autoscaling per le tue esigenze.
Monitoraggio delle prestazioni:
risolvi i problemi e ottimizza in base a metriche chiave come latenza, throughput, utilizzo delle risorse e integrità del modello.

Cloudera AI Inference ti permette di sbloccare il pieno potenziale dei dati su larga scala con l'esperienza AI di NVIDIA e di proteggerli con funzionalità di sicurezza di livello aziendale, in modo da poter salvaguardare i dati in tutta sicurezza ed eseguire carichi di lavoro on premise o nel cloud, implementando modelli AI in modo efficiente con la flessibilità e la governance necessarie.
Unisciti a noi
Fai il passo successivo
Esplora le potenti funzionalità e approfondisci i dettagli con risorse e guide che ti permetteranno di iniziare rapidamente.
Tour del prodotto AI Inference Service
Ottieni uno sguardo approfondito sul servizio Cloudera AI Inference.
Documentazione del servizio di inferenza AI
Scopri tutto, dalle descrizioni delle funzionalità alle guide utili per l'implementazione.
Esplora altri prodotti
Accelera il processo decisionale basato sui dati, dalla ricerca alla produzione, con una piattaforma protetta, scalabile e aperta per l'AI aziendale.
Sblocca flussi di lavoro privati di AI generativa e agentic AI per qualsiasi livello di competenza, con velocità di sviluppo low-code e controllo completo del codice.
Porta la potenza dell'AI nella tua azienda in modo sicuro e su larga scala, garantendo che ogni informazione sia rintracciabile, spiegabile e affidabile.
Esplora il framework end-to-end per la creazione, l'implementazione e il monitoraggio istantaneo di applicazioni ML pronte all'uso.