
Sviluppo di applicazioni RAG: il diavolo è nei dettagli
La creazione di applicazioni di Retrieval-Augmented Generation (RAG) può diventare molto complessa, poiché richiede una gestione attenta dell'immissione, dell'elaborazione e del recupero dei dati. Tradizionalmente, gli sviluppatori hanno affrontato questa procedura suddividendo i dati in blocchi, inserendo gli incorporamenti e integrando i database vettoriali.
Tuttavia, una delle insidie più comuni nell'implementazione di una soluzione RAG è non capire l'interdipendenza delle diverse componenti. Gli sviluppatori dovrebbero porsi la domanda: «I nostri dati possono essere suddivisi così come sono, oppure dovremmo perfezionarli prima di suddividerli?»
Cloudera Data Flow e i processori esclusivi RAG Pipeline di Cloudera semplificano il complesso processo di perfezionamento dei dati non strutturati attraverso il partizionamento, consentendo una suddivisione più efficace e incorporamenti vettoriali di qualità superiore. Una partizione mal progettata o una suddivisione in blocchi possano danneggiare le prestazioni e la qualità dell'incorporamento. Per evitare questo problema, gli strumenti di Cloudera astraggono gran parte di questa complessità, semplificando lo sviluppo di soluzioni RAG efficienti e affidabili.
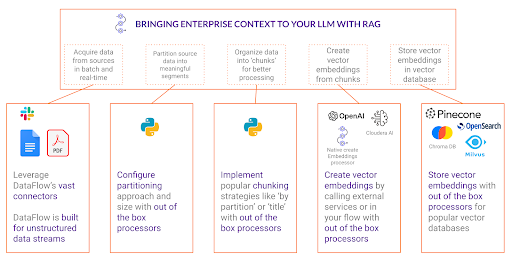
Esploriamo le fasi critiche di un flusso di lavoro RAG (partizionamento, suddivisione in blocchi, incorporamento e immissione) e dimostriamo come la tecnologia di Cloudera semplifichi ciascuna di esse.
Partizionamento dei dati: Le fondamenta del RAG
Il primo, fondamentale passaggio in un flusso di lavoro RAG è il partizionamento. Questo processo comporta la suddivisione di fonti di dati di grandi dimensioni e talvolta non strutturate in segmenti significativi, consentendo l'iterazione programmatica sui dati non strutturati. Naturalmente, il processo di recupero è possibile anche senza partizionamento, ma maggiore è il controllo granulare sull'elaborazione, maggiore sarà la flessibilità per creare flussi per diverse origini di dati. Il partizionamento garantisce che i dati siano organizzati in porzioni gestibili, in linea con il modo in cui gli utenti interrogano le informazioni.
Le strategie di creazione delle partizioni variano a seconda della natura dei dati. Ad esempio, la suddivisione per intestazioni di sezione consente un recupero più organizzato quando si elaborano documenti lunghi, come i manuali per gli utenti. In alternativa, il partizionamento può comportare la suddivisione dei contenuti per timestamp per preservare il flusso conversazionale per dati come i log delle chat. Un altro aspetto fondamentale da considerare sono i limiti dei token: poiché la maggior parte dei modelli di incorporamento ha una quantità predefinita di token che può essere elaborata contemporaneamente, il partizionamento deve allinearsi a questi vincoli per garantire prestazioni ottimali.
Un approccio di partizionamento ben definito aiuta a mantenere l'accuratezza, l'efficienza e l'usabilità delle applicazioni RAG. Gli sviluppatori possono ottimizzare la qualità delle risposte assicurandosi che solo i dati più pertinenti vengano recuperati e trasmessi all'LLM, riducendo al minimo il sovraccarico computazionale superfluo.
Suddivisione: garantire la preservazione del contesto
Una volta completato il partizionamento, il passo successivo è la suddivisione. Il chunking consiste nel raggruppare partizioni correlate per mantenere un contesto significativo. Mentre il partizionamento spezza il contenuto in componenti fondamentali, la suddivisione assicura che questi componenti mantengano le loro relazioni, prevenendo la perdita di contesto.
Ad esempio, una clausola o un regolamento può estendersi su più paragrafi nei documenti legali. Se le partizioni sono troppo strette, il significato potrebbe andare perso quando si recupera il contenuto in base alla query di un utente. La suddivisione aiuta a raggruppare i segmenti di testo correlati in un'unità completa e logica facendo sì che, quando un utente pone una domanda, il modello riceva informazioni contestuali sufficienti per generare una risposta accurata e pertinente.
Le strategie di chunking variano a seconda della natura del dataset. Alcuni approcci prevedono una semplice suddivisione a lunghezza fissa, in cui i segmenti sono raggruppati in base a un numero predefinito di token. Le strategie più avanzate possono prevedere la suddivisione del titolo di un documento in blocchi insieme al testo correlato.
Una suddivisione efficace migliora la precisione della ricerca, ottimizza la latenza di recupero e garantisce che le risposte generate dagli LLM siano contestualizzate e precise. Inoltre, determinando una strategia di suddivisione che massimizza la conservazione del contesto, si può informare la decisione del proprio modello di incorporazione con la conoscenza predeterminata delle dimensioni dei blocchi.
Incorporamento: trasformare il testo in vettori ricercabili
Con blocchi ben strutturati, il passo successivo nel flusso di lavoro RAG è l'incorporamento, o embedding. Gli incorporamenti sono rappresentazioni numeriche del testo che consentono alle macchine di comprendere e confrontare il significato semantico di diversi segmenti di testo. Senza di essi, le applicazioni RAG sarebbero limitate a semplici ricerche per parole chiave, che mancano della comprensione contestuale propria di un vero recupero semantico.
L'embedding è un processo in più fasi che coinvolge la tokenizzazione, la trasformazione vettoriale e l'archiviazione. Quando un blocco di testo passa attraverso un modello di incorporamento, viene prima suddiviso in token che vengono poi convertiti in un vettore ad alta dimensionalità che cattura l'essenza del testo in un formato adatto per ricerche di somiglianza matematica, come la distanza euclidea (L2) e la similarità coseno.
La scelta del modello di incorporamento corretto è cruciale. Alcuni modelli sono ottimizzati per il recupero generico, mentre altri sono perfezionati per applicazioni domain-specific, per esempio nei documenti legali, medici o tecnici. Un'altra considerazione chiave è la dimensionalità del vettore, che deve essere conforme allo schema del database vettoriale. Una discrepanza nelle dimensioni del vettore può causare ricerche inefficienti o problemi di compatibilità.
Una volta che i blocchi di testo sono incorporati in rappresentazioni vettoriali, diventano ricercabili utilizzando metriche di similarità. Questo consente un recupero altamente efficiente dei contenuti più rilevanti in base alle query degli utenti, migliorando notevolmente l'accuratezza e la reattività delle applicazioni basate su RAG.
Cloudera Data Flow offre un processore di incorporamento incredibilmente potente ma facile da usare che potenzia le capacità dei tuoi flussi di dati, consentendoti di sfruttare un modello nel contesto del processore. Non è necessaria un'API (non è richiesta una GPU). Il processore ha tre semplici proprietà:
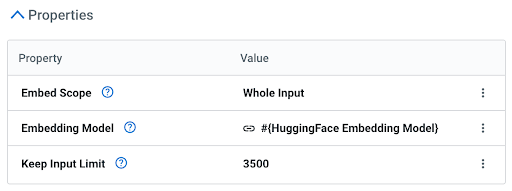
Questo ti offre un controllo granulare per scegliere il miglior modello di incorporamento per ogni flusso di dati.
Inserimento dei blocchi incorporati in un database vettoriale: abilitare un recupero efficiente
L'ultimo passaggio nel flusso di lavoro RAG è l'inserimento dei blocchi incorporati in un database vettoriale. I database vettoriali sono progettati per eseguire ricerche di somiglianza ad alta velocità, consentendo il recupero efficiente di contenuti rilevanti quando un utente effettua una query.
A differenza dei database tradizionali, che si basano sull'indicizzazione strutturata per ottenere corrispondenze esatte, i database vettoriali sfruttano le ricerche di somiglianza e algoritmi, come ANN e KNN, per trovare gli incorporamenti che corrispondono strettamente alla query dell'utente. Questo è ciò che permette alle applicazioni RAG di recuperare contenuti semanticamente rilevanti, anche se la formulazione della query è diversa dal testo memorizzato.
Una volta che i dati incorporati sono stati inseriti nel database vettoriale, il sistema è pronto per ricevere le query in tempo reale. Quando un utente invia una richiesta, la query viene trasformata in un incorporamento, viene confrontata con i vettori memorizzati e vengono recuperati i risultati più rilevanti, che costituiscono la base della risposta dell'LLM.
Cloudera Data Flow offre numerosi processori di connessione VectorDB come Milvus, Pinecone e Chroma (e altri che arriveranno in futuro).
Semplifica lo sviluppo delle tue applicazioni RAG oggi stesso
Con Cloudera Data Flow e i suoi processori specializzati RAG Pipeline, le organizzazioni possono ora creare, distribuire e ottimizzare le applicazioni RAG con una facilità senza precedenti. Astraendo gran parte della complessità tecnica, le soluzioni di Cloudera consentono agli sviluppatori di concentrarsi sul miglioramento della precisione del recupero, sull'ottimizzazione della generazione delle risposte e sul miglioramento dell'esperienza complessiva dell'utente.
Le aziende possono implementare rapidamente soluzioni RAG che si scalano in modo efficiente e forniscono risposte precise e contestualizzate sfruttando i processori esclusivi di partizionamento, suddivisione in blocchi, incorporamento e integrazione VectorDB di Cloudera.
Per scoprire in che modo Cloudera può aiutarti a semplificare lo sviluppo delle applicazioni RAG, contatta il nostro team per richiedere una demo o consulta la nostra documentazione tecnica per ulteriori informazioni.
Seguiteci per un nuovo approfondimento sulle tecniche avanzate di ottimizzazione RAG!
Scopri di più:
Per esplorare le nuove funzionalità di Cloudera Data Flow 2.9 e scoprire come può trasformare le tue pipeline di dati, guarda questo video.
