
Le fondamenta aperte di Cloudera consentono alle organizzazioni di accedere al 100% dei propri dati, ovunque risiedano.
In diversi settori, i team dati stanno ripensando come costruire e gestire sistemi che facciano più che immagazzinare informazioni: vogliono trasformare i dati in intelligence. Altrettanto importante è che questi sistemi interagiscano. I modelli di AI, le pipeline di funzionalità, i report di business intelligence (BI) e i lavori batch spesso coinvolgono più team e motori. Condividere i dati oltre questi confini senza copiarli o modificarli è ormai un requisito di primo ordine.
Tradizionalmente, le organizzazioni si sono basate su un'architettura a due livelli: data warehouse ottimizzati per BI e reporting e data lake progettati per AI su larga scala e machine learning (ML). Questa separazione ha avuto un costo: movimentazione complessa dei dati, ingegneria specializzata e archiviazione duplicata tra sistemi che raramente rimanevano sincronizzati.
L'architettura open lakehouse di Cloudera affronta questa sfida, unendo carichi di lavoro analitici (BI, query ad hoc) e AI (AI predittiva e generativa, o GenAI) su un'unica base dati governata. Con formati di tabella aperta come Apache Iceberg, questa architettura unificata dei dati consente alle organizzazioni di portare il calcolo ai dati (non il contrario) e fornisce la base per eseguire carichi di lavoro AI più vicini ai dati. I carichi di lavoro AI sul lakehouse possono operare direttamente su dati governati, versionati e di alta qualità.
Cloudera è l'unica azienda di piattaforme di dati e AI che porta l'AI ai dati ovunque si trovino. Sfruttando la nostra solida base open source collaudata, offriamo un'esperienza cloud coerente che unisce cloud pubblici, data center e edge.
L'importanza delle basi aperte per l'esecuzione dei carichi di lavoro di AI
Nell'ultimo decennio, le aziende hanno imparato che prestazioni e scalabilità da sole non sono sufficienti e che flessibilità e interoperabilità determinano il successo a lungo termine. I carichi di lavoro dell'AI, in particolare, dipendono dalla capacità di utilizzare fonti di dati, framework e strumenti disparati senza essere vincolati da formati o sistemi proprietari.
È qui che i formati di tabelle aperte come Apache Iceberg hanno rimodellato l'architettura delle piattaforme di dati. Iceberg separa la definizione logica di una tabella dal layout di archiviazione fisica, consentendo a più motori e framework di leggere e scrivere gli stessi dati con garanzie transazionali complete. Questa apertura permette di far evolvere l'infrastruttura e adottare nuovi motori di calcolo senza riscrivere le pipeline.
L'esecuzione di pipeline di livello produttivo richiede una piattaforma unificata in grado di collegare dati, modelli e governance in ogni fase del ciclo di vita dell'AI. Al centro ci sono pipeline di data e feature engineering che trasformano continuamente dati grezzi strutturati, semi-strutturati e non strutturati in funzionalità pronte per l'AI, mantenendo lineage e riproducibilità per l'addestramento e la valutazione del modello.
Oltre all'ML tradizionale, la GenAI introduce nuovi requisiti operativi. I team hanno bisogno di infrastruttura e accesso ai dati per la retrieval-augmented generation (RAG), la messa a punto di modelli linguistici di grandi dimensioni (LLM) su dati privati e la costruzione di flussi di lavoro basati su agenti che combinino modelli, prompt e protocolli di contesto modello (MCP) (API) per risolvere compiti specifici di dominio. Questi carichi di lavoro si basano sia su dati tabellari che non strutturati (testo, documenti, immagini e incorporazioni), tutti governati sotto un unico piano dati e metadati. Inoltre, un livello di inferenza scalabile è essenziale per distribuire e servire questi modelli in modo sicuro ed efficiente.
Man mano che i carichi di lavoro dell'AI diventano sempre più multimodali e agentici, l'accesso a cataloghi e metadati diventa altrettanto cruciale. Pipeline di AI, sistemi di recupero e agenti autonomi si affidano tutti ai metadati per scoprire dataset, riprodurre gli stati di addestramento e mantenere le genealogie. Un catalogo aperto offre a questi sistemi un modo universale di interrogare, registrare e tenere traccia dei set di dati, indipendentemente da dove o come vengono elaborati.
La base aperta di Cloudera consente alle organizzazioni di supportare l'intero spettro di carichi di lavoro analitici, predittivi e GenAI.
Piattaforma unificata di dati e intelligenza artificiale di Cloudera
L'open data lakehouse di Cloudera unifica l'ingegneria dei dati, l'analisi e l'AI sulla stessa architettura governata, basandosi su basi aperte come Apache Iceberg e il catalogo REST. La piattaforma è progettata attorno al principio che i carichi di lavoro (analitici o di AI) devono operare dove i dati già si trovano. Eliminando l'attrito dello spostamento o della duplicazione dei dati, i team possono costruire pipeline continue che abbracciano l'ingestione, la trasformazione, l'analisi e le operazioni sui modelli, con un lineage e una governance completi.
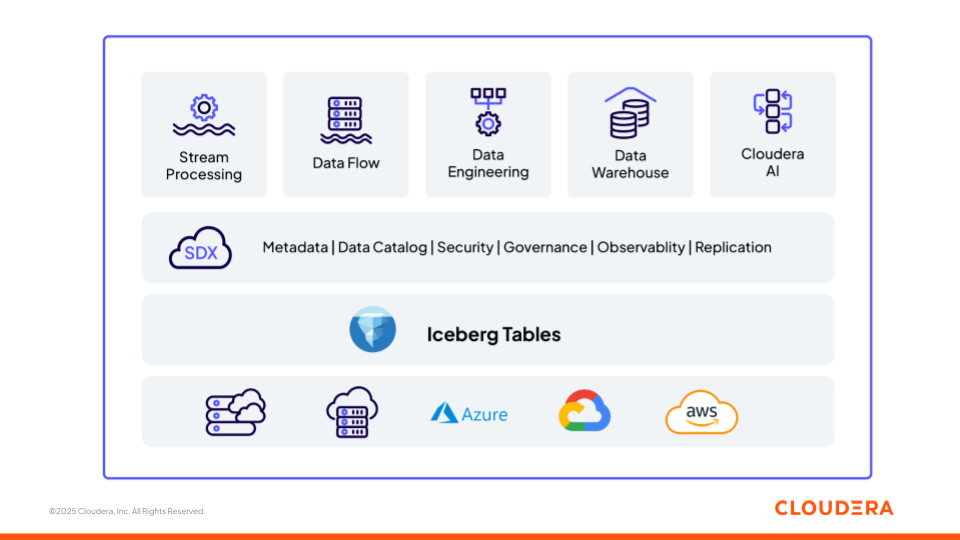
Figura 1: Piattaforma di dati e AI di Cloudera costruita su basi aperte (Apache Iceberg)
Ora rivediamo come i diversi componenti della piattaforma Cloudera (Figura 1) supportino i team nella costruzione di pipeline ML e applicazioni di GenAI, così come le diverse fasi del ciclo di vita dei dati e dell'AI (dall'ingerenza all'inferenza) operando come un'unica piattaforma interoperabile. Ogni componente è costruito su standard aperti, garantendo flessibilità e interoperabilità tra gli ambienti.
Archiviazione: Apache Iceberg
Apache Iceberg è il formato di tabella aperto, transazionale e con versioni controllate che sostiene l'architettura lakehouse di Cloudera. Iceberg consente l'evoluzione degli schemi, i viaggi nel tempo e le operazioni atomiche, consentendo sia ai carichi di lavoro analitici che AI di operare costantemente sugli stessi dati governati. Cloudera offre una base governata con versioni controllate che garantisce che ogni modello, prompt o compito di recupero attinga a una visione coerente e tracciabile dei dati.
Le capacità native di Iceberg, come l'evoluzione degli schemi, sono anch'esse strettamente allineate a come evolvono i set di dati dell'AI. I negozi di funzionalità, i set di dati di training e i corpora di recupero possono tutti condividere le stesse tabelle Iceberg nel lakehouse di Cloudera, utilizzando gli snapshot per congelare viste coerenti per il training, mentre i nuovi dati continuano a fluire per l'inferenza. Questo elimina la divisione tra tabelle analitiche e archiviazione specifica per l'AI.
Ingestione: dati Cloudera in movimento
Cloudera DataFlow, basato su Apache NiFi, costituisce la base per il trasferimento continuo dei dati nella lakehouse. Consente l'acquisizione a bassa latenza da fonti aziendali diverse (database, API, dispositivi IoT e event log) per supportare sia carichi di lavoro batch che di streaming. Le recenti innovazioni nell'integrazione nativa di Apache Iceberg di NiFi ora permettono di scrivere dati direttamente nell'open lakehouse senza staging intermedio. Questo stretto accoppiamento tra NiFi e Iceberg riduce la complessità del pipeline e avvicina l'ingestione al formato di tabella aperta stesso.
Nei casi d'uso in tempo reale, NiFi, Apache Kafka e Apache Flink formano un tessuto di ingestione guidato dagli eventi: NiFi orchestra e instrada i dati, Kafka fornisce uno streaming duraturo e Flink consente l'arricchimento in tempo reale prima di persistere i dati in Iceberg. Questo design assicura che i dati rimangano sia aggiornati che governati per tutti i consumatori downstream. Questo flusso continuo di dati multimodali è ciò che alimenta anche i carichi di lavoro di intelligenza artificiale sul lakehouse. Rendendo i dati in tempo reale disponibili in modo continuo nelle tabelle Iceberg con una governance coerente, le aziende possono fornire ai sistemi GenAI informazioni tempestive e specifiche per dominio, rendendo pipeline RAG e workflow agentici più precisi, radicati e affidabili.
Catalogo: Cloudera Iceberg REST Catalog
Il Cloudera Iceberg REST Catalog (basato sulla specifica open REST) fornisce un servizio di metadati centralizzato e interoperabile che consente a qualsiasi motore di terze parti (come Snowflake, Redshift e Databricks) che supporta la specifica aperta di avere accesso zero-copy alle tabelle Iceberg. Questo è un aspetto chiave per le organizzazioni, in quanto non sono limitate a un solo motore di calcolo offerto da un'unica piattaforma e quindi hanno la flessibilità di scegliere il miglior computer per l'attività. Gli utenti possono utilizzare i loro strumenti preferiti, mentre le stesse policy di sicurezza e governance offerte da Cloudera seguono i dati ovunque, garantendo coerenza in tutti gli ambienti.
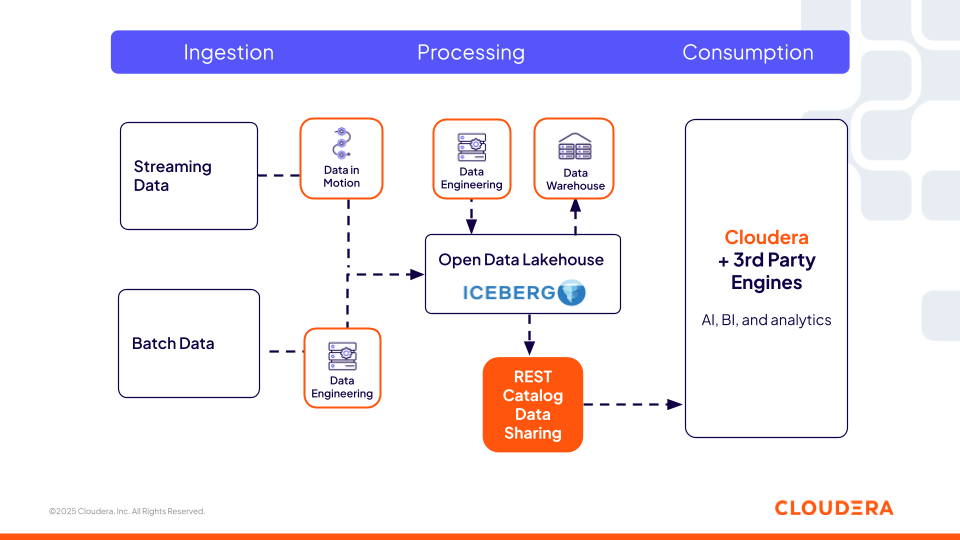
Figura 2: il catalogo REST Iceberg di Cloudera consente l'interoperabilità con motori di terze parti.
Questo livello di catalogo è fondamentale per pipeline di feature engineering, flussi di lavoro basati su agenti e sistemi di recupero per localizzare e accedere dinamicamente ai dataset governati. Gli agenti di AI possono interrogare le tabelle Iceberg utilizzando il catalogo REST proprio come un knowledge graph dei dati aziendali. Possono scoprire le tabelle disponibili, interpretare i loro schemi e ragionare sui metadati delle tabelle, come partizionamento, istantanee e lineage, per determinare quali dataset utilizzare.
Sicurezza e governance: Cloudera SDX
Cloudera Shared Data Experience (SDX) è il framework unificato di sicurezza e governance che copre ogni servizio, dall'ingestione all'inferenza. SDX fornisce uno strato unico e coerente per la lineage dei dati, l'audit, il controllo degli accessi e l'applicazione delle policy, garantendo che ogni carico di lavoro erediti lo stesso modello di sicurezza indipendentemente da dove venga eseguito. Si integra con i sistemi di identità aziendali (LDAP, SSO, OAuth) e supporta controlli di accesso dettagliati, basati su ruoli e attributi, su dati strutturati e non strutturati.
Collegando SDX con la base open lakehouse, Cloudera assicura che dati, modelli e agenti AI operino all'interno dello stesso confine governato, offrendo trasparenza, riproducibilità e fiducia per entrambi i carichi di lavoro analitici e GenAI.
Servizi dati e AI di Cloudera
Il livello dei servizi unificati riunisce tutte le capacità funzionali di cui i team hanno bisogno per trasformare, analizzare e rendere operativa l'AI, il tutto lavorando sugli stessi dati governati.
Data Engineering
Cloudera Data Engineering, basato su Apache Spark e Apache Airflow open-source, offre un servizio serverless per costruire, orchestrare e scalare pipeline di dati direttamente su tabelle Iceberg, abilitando pipeline ETL e feature affidabili e riproducibili per carichi di lavoro di analytics e IA in ambienti ibridi.
Servizi AI
Il livello di servizi AI di Cloudera rende operativo l'intero ciclo di vita dell'AI, partendo dall'addestramento e dalla messa a punto dei modelli fino alla distribuzione sicura, il tutto eseguito in modo nativo sulla stessa base di dati governata con Iceberg. Unifica lo sviluppo del modello, il registro e l'inferenza in un unico flusso di lavoro che collega l'ingegneria dei dati e le operazioni di AI.
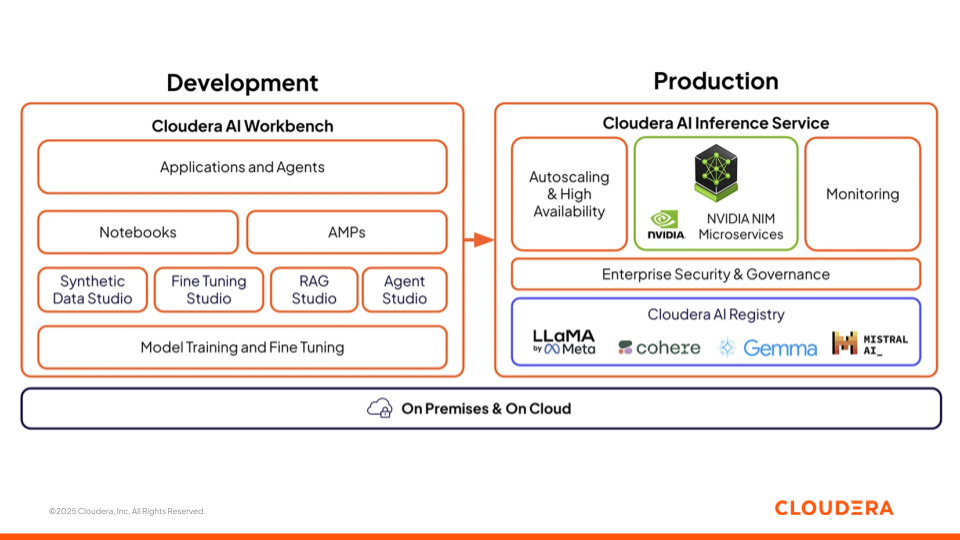
Figura 3: Offerta di Cloudera AI con AI Workbench e Inference Service
Cloudera AI Workbench
Cloudera AI Workbench è l'ambiente collaborativo in cui data scientist, analisti e ingegneri sviluppano, perfezionano e testano modelli. Riunisce notebook, generatori di applicazioni low-code (AMP) e studi specializzati per ogni fase dello sviluppo dell'intelligenza artificiale. Per accelerare lo sviluppo e la distribuzione dell'intelligenza artificiale, Cloudera AI Workbench sostiene quattro studi di AI che colmano il divario tra team aziendale e tecnici, favorendo la collaborazione nei progetti di AI.
- Synthetic Data Studio genera set di dati sintetici per test e addestramento di modelli quando i dati reali sono limitati o ristretti.
- Fine-Tuning Studio adatta modelli a base aperta con set di dati specifici per l'azienda per maggiore rilevanza e accuratezza.
- RAG Studio crea pipeline RAG che collegano gli LLM (come OpenAI, Anthropic, Amazon Bedrock) ai dati privati pertinenti per risultati contestuali e fondati.
- Agent Studio consente la creazione di flussi di lavoro basati su agenti a più fasi che utilizzano modelli, MCP, API e fonti di dati interne per automatizzare attività specifiche del dominio.
Tutte queste funzionalità operano sull'open lakehouse (sulle basi di Iceberg), garantendo ai team un accesso controllato e senza copia ai dati necessari per attività specifiche.
Server Cloudera MCP
Cloudera sta inoltre ampliando l'apertura della sua piattaforma AI attraverso una serie di servizi MCP emergenti, a partire dal server open-source Cloudera AI Workbench MCP. Questo servizio è progettato per l'integrazione di sistemi AI, consentendo funzionalità agentiche e di chiamata di strumenti all'interno dell'AI Workbench. Fornisce il framework che consente agli LLM di interagire in modo sicuro con le funzionalità e i componenti di Cloudera AI Workbench, integrando modelli, dati e applicazioni nei flussi di lavoro aziendali automatizzati. In questa architettura, gli agenti intelligenti possono ragionare, agire e automatizzare compiti nell'ambiente Cloudera fidato e governato, mantenendo al contempo la sicurezza, il controllo e l'auditabilità richiesti nei settori regolamentati.
Cloudera AI Inference Service
Il Cloudera AI Inference Service porta in produzione i modelli con autoscaling, alta disponibilità e osservabilità end-to-end. Supporta sia i modelli ML tradizionali sia i modelli linguistici di grandi dimensioni (LLM), fornendo previsioni e risposte con bassa latenza. I modelli possono essere distribuiti come endpoint REST o gRPC con sicurezza di livello aziendale, garantendo un accesso affidabile e coerente da applicazioni e agenti.
Cloudera AI Registry, integrato all'interno dello strato di inferenza, fornisce una gestione centralizzata del ciclo di vita del modello con API compatibili con MLflow per il tracciamento, il versioning, l'archiviazione degli artefatti e la lineage. Può scegliere tra vari modelli linguistici aperti e aziendali, come LlaMa, Cohere, Gemma, Mistral.
Il livello di inferenza include anche il monitoraggio e l'osservabilità integrati, consentendo ai team di monitorare la latenza, il throughput e la deriva del modello, mantenendo al tempo stesso un lignaggio e una conformità completi attraverso la governance SDX. Questo garantisce che le previsioni dei modelli siano spiegabili e tracciabili, un requisito chiave per l'AI di livello enterprise.
Il futuro è guidato dall'intelligenza artificiale e l'intelligenza artificiale è alimentata da tutti i dati
Il successo dell'IA dipende tanto dall'architettura dei dati quanto dalla capacità modello/agente. Il lakehouse fornisce questa base, unificando i carichi di lavoro analitici, operativi e di AI su un unico piano dati governato. Quando costruito su standard aperti, garantisce che dati, metadati e modelli possano interagire tra strumenti, cloud e team senza attrito.
Insieme, Cloudera AI Workbench, AI Inference Service e l'integrato AI Registry completano il ciclo di vita dal dato all'AI su una base open lakehouse. Costruito direttamente su tabelle Iceberg governate e accesso aperto ai metadati, questo stack garantisce che ogni modello, prompt e agente operi su dati affidabili e versionati.
Il futuro dell'AI aziendale non sarà definito da stack proprietari, ma da basi aperte che unificano i dati, la governance e l'intelligenza attraverso standard condivisi e interoperabilità trasparente.
Per saperne di più su come preparare, integrare e analizzare i dati su larga scala in modo sicuro con Cloudera, prova le nostre demo di prodotto o iscriviti a una prova gratuita di 5 giorni.
