Sbloccare il potenziale dell'AI aziendale: Knowledge Distillation per gli analytics per il supporto clienti





Oggi le imprese affrontano una sfida ardua: vogliono sfruttare modelli avanzati di AI per mantenere la competitività, ma devono controllare i costi elevati dei modelli linguistici di grandi dimensioni (LLM) basati sul cloud e rispettare le normative sulla privacy dei dati.
Quindi, come possono le aziende esplorare le innovazioni dell'AI senza sforare i budget o esporre dati sensibili e privati? Noi di Cloudera abbiamo sviluppato una soluzione che trasforma questa sfida in un'opportunità: utilizzando dati sintetici generati da dati privati e la knowledge distillation per costruire sistemi di AI efficienti dal punto di vista dei costi, accurati e conformi.
In questo articolo, vedremo come il Synthetic Data Generation Studio di Cloudera, parte di Cloudera AI Studios, consenta alle organizzazioni di sfruttare l'innovazione dell'AI anche quando i dati del mondo reale sono pochi o sensibili.
Caso d'uso e punti chiave
Caso d'uso: appoggiandoci a un caso d'uso interno, mostreremo come abbiamo migliorato le prestazioni e il throughput complessivo per la pipeline di ticket di assistenza clienti di Cloudera attraverso la knowledge distillation utilizzando dati sintetici generati da dati privati, garantendo al contempo la privacy dei dati e la conformità normativa.
Punti chiave:
La privacy dei dati come vantaggio competitivo: i dati sintetici permettono l'innovazione senza rischi normativi.
Prestazioni convenienti: i modelli più piccoli e ottimizzati superano le alternative più grandi e ad alto consumo di risorse.
Applicabile a più casi d'uso: lo stesso approccio può supportare casi d'uso che vanno dal rilevamento delle frodi al servizio clienti personalizzato.
Sfida aziendale: bilanciare la velocità e la precisione del modello di intelligenza artificiale senza compromettere la privacy dei dati
Il team di assistenza clienti di Cloudera utilizza modelli di AI per analizzare e riassumere i ticket di supporto in tempo reale. Il sistema accetta come input i commenti dei clienti o degli agenti di assistenza di Cloudera. Quindi, analizza ogni commento ed estrae una serie di dati analitici, come il sentiment e il riepilogo. Queste analisi sono fondamentali per migliorare l'esperienza dei clienti presso Cloudera.
A causa della natura sensibile dei dati dei clienti elaborati in questa pipeline, è possibile utilizzare solo modelli eseguiti in ambienti locali e non è consentito condividere i dati dei clienti con fonti esterne.
Inizialmente, per analizzare i commenti, il team si affidava agli LLM locali (Goliath 120B), che soddisfacevano i requisiti di prestazioni di base, ma erano carenti in termini di velocità e prestazioni di generazione: in media, l'elaborazione delle richieste richiedeva 12-15 secondi ciascuna e le richieste arrivavano ogni 30 secondi. L'aderenza al risultato previsto è stata del 77,5% e l'accuratezza della generazione era inferiore rispetto ai modelli proprietari, il che bloccava la scalabilità e le prestazioni degli LLM.
Le sfide dell'uso dei grandi LLM locali (Goliath-120B) erano evidenti: tempi di risposta più lenti, costi più alti, minore precisione di generazione rispetto ai modelli all'avanguardia basati su cloud e rischi di conformità.
Anche le grandi organizzazioni affrontano compromessi simili, trovandosi a bilanciare accuratezza e velocità dell'AI con i rischi di esposizione dei dati.
Soluzione di Cloudera: Knowledge Distillation con dati privati
La svolta di Cloudera risiede in un approccio alla knowledge distillation incentrato sulla privacy.
Invece di addestrare i modelli su dati grezzi dei clienti, che comportavano rischi normativi e di esposizione, abbiamo generato set di dati sintetici utilizzando Cloudera Synthetic Data Studio. Questo nuovo strumento low-code in Cloudera AI ha imitato interazioni del mondo reale, come domande tecniche, scenari di risoluzione dei problemi e altro ancora, senza mai esporre informazioni private.
La generazione di interazioni sintetiche con l'assistenza clienti ha permesso di godere di vantaggi normativi e di esposizione: il team ha potuto inviare i dati sintetici a LLM all'avanguardia basati sul cloud per estrarre informazioni come il sentiment dei clienti dagli LLM con le migliori prestazioni. Questi LLM basati su cloud hanno fornito un'estrazione delle informazioni molto più accurata rispetto ai grandi LLM locali, rendendoli una fonte ideale per distillare informazioni accurate da questi LLM all'avanguardia.
La soluzione di dati sintetici di Cloudera ha eliminato qualsiasi rischio di conformità e privacy e ha generato dati sintetici della massima qualità (anche superiori rispetto agli LLM locali di grandi dimensioni esistenti). Questo approccio ha introdotto la possibilità di distillare informazioni da modelli all'avanguardia a piccoli LLM e risolvere lo stesso problema di Goliath-120B, ma a un costo inferiore e con maggiore precisione.
Il nostro processo
Generazione dei dati: utilizzando il flusso di lavoro di generazione dei dati di Synthetic Data Studio, abbiamo creato un prompt che istruiva Claude Sonnet a generare domande e risposte dei clienti. Il prompt istruisce l'LLM a creare domande e risposte per l'assistenza clienti, a imporre il tono e a dettagliare la struttura. Inoltre, forniamo un elenco di argomenti che compaiono nei dati del mondo reale (come l'assistenza clienti per Cloudera AI o Cloudera Data Warehouse) e utilizziamo argomenti iniziali per garantire la generazione di ticket di assistenza clienti diversificati e reali.
Ottimizzazione: utilizzando solo i dati filtrati, il team ha suddiviso i dati in addestramento e sviluppo, testati e distillati dal modello Claude Sonnet a un modello Meta Llama3.1-8B-instruct. Il team ha condotto diversi esperimenti selezionando i parametri di ottimizzazione che massimizzano le prestazioni dell'LLM distillato.
Valutazione: utilizzando il flusso di lavoro di valutazione di Synthetic Data Studio, il team ha creato un prompt per istruire un LLM-as-a-judge su come valutare la qualità dei dati generati e ha filtrato i campioni di bassa qualità.
Utilizzando sia valutazioni umane che automatiche di LLM-as-a-judge, il team ha valutato le domande e le risposte dei ticket di assistenza clienti del mondo reale. Il team di Cloudera si è concentrato sulle risposte in cui gli LLM distribuiti e distillati differivano e ha riportato il tasso di successo di ciascuno. Inoltre, ha misurato i miglioramenti della velocità in termini di tempo medio di esecuzione, aderenza all'output previsto e costo per distribuire il modello.
I risultati
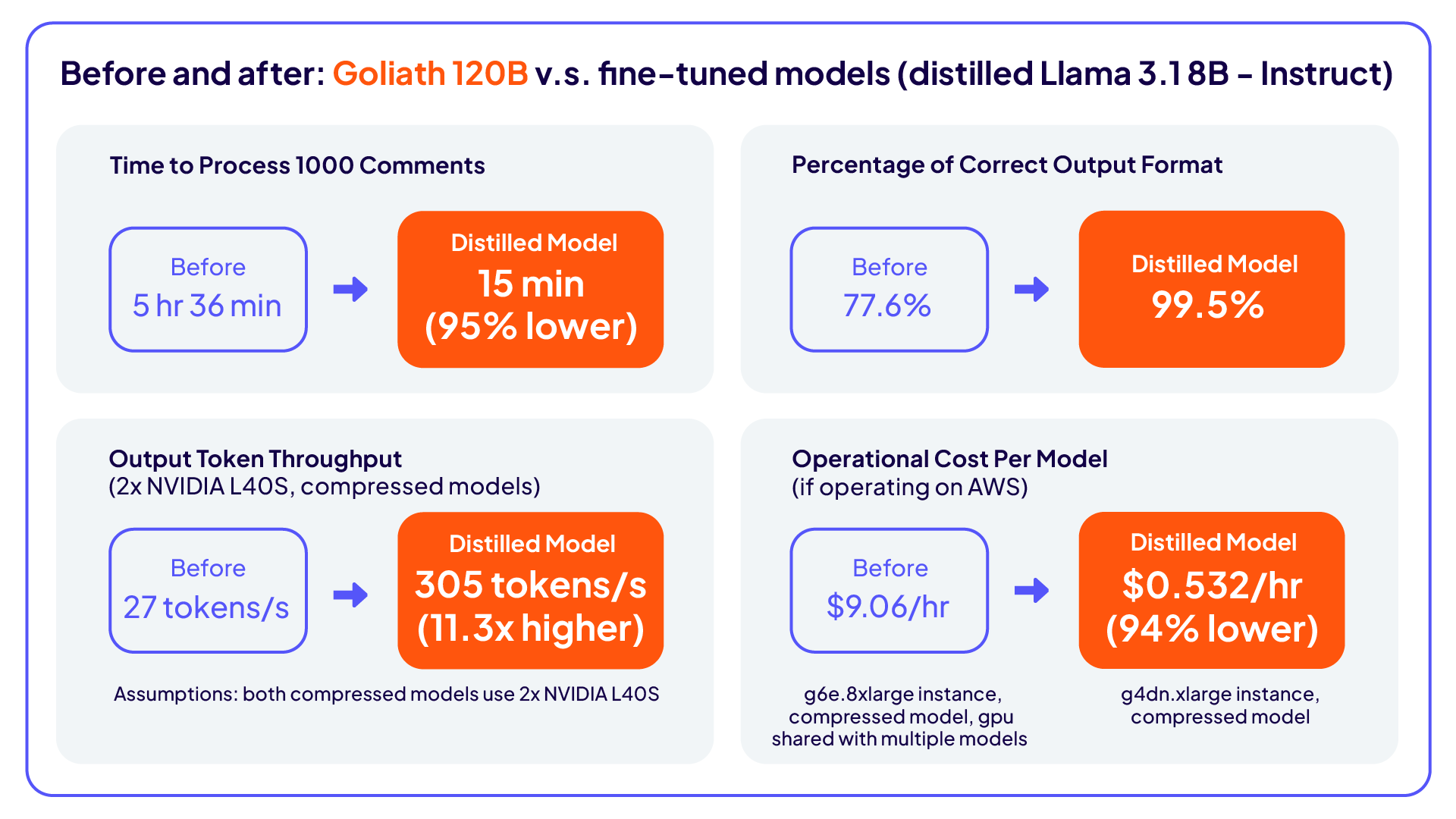
Velocità migliorata: il tempo di elaborazione è diminuito del 95%.
Migliore struttura dell'output: l'aderenza all'output è aumentata dal 77,5% al 99,5%.
Maggiore accuratezza dell'LLM: confrontando il più piccolo LLM distillato (Llama 3.1 8B) con l'LLM Goliath distribuito (Goliath 120B), il tasso di successo è stato del 70% contro il 30% quando si utilizza Phi-4 come giudice e del 63% contro il 37% quando si utilizzano valutatori umani per confrontare i due modelli.
Costi ed efficienza migliorati: l'LLM distillato più piccolo ha ridotto le esigenze di elaborazione e memoria, aumentando la scalabilità in tempo reale, mantenendo la privacy dei dati e migliorando il throughput di 11 volte.
I risultati parlano chiaro: le imprese possono raggiungere l'eccellenza nell'AI senza compromettere la privacy dei dati. Sintetizzando i dati di addestramento e distillando le conoscenze, possono evitare compromessi tra innovazione e conformità.
I dati sintetici consentono l'innovazione senza rischi normativi.
Sviluppando un approccio di knowledge distillation, Cloudera ha ottenuto una riduzione del 95% dei tempi di elaborazione, ha aumentato l'aderenza alla struttura di output al 99,5% e ha implementato un modello distillato Llama 3.1 8B che ha superato il precedente modello Goliath 120B del 70% in accuratezza (secondo Phi-4) e del 63% nelle valutazioni umane.
Questo metodo ha eliminato i rischi di conformità evitando l'uso diretto di dati sensibili e ha inoltre sbloccato un throughput 11 volte maggiore, dimostrando che modelli più piccoli e ottimizzati possono superare alternative più grandi e ad alta intensità di risorse sia in termini di velocità che di precisione.
Prova il nostro AMP per esplorare come utilizzare i dati sintetici privati per distillare conoscenza da un modello di grandi dimensioni a uno più piccolo per un caso d'uso di supporto clienti.