Apache Tez
Un framework per applicazioni di elaborazione dati basate su YARN,Invio Hadoop
Apache™ Tez è un framework estensibile per la creazione di applicazioni batch e di elaborazione interattiva di dati ad alte prestazioni, coordinato da YARN in Apache Hadoop. Tez migliora il paradigma di MapReduce aumentando drasticamente la velocità, pur mantenendo la capacità di MapReduce di ridimensionare la mole di dati a livello di petabyte. Apache Tez è utilizzato da importanti progetti dell'ecosistema Hadoop come Apache Hive e Apache Pig e da un numero crescente di applicazioni di accesso ai dati di terze parti sviluppate per l'ecosistema Hadoop nel suo complesso.
Hive con Tez
Affermatosi standard di fatto per SQL in Hadoop, Apache Hive è ottimale per query batch e interattive su moli di dati a livello di petabyte. Hive incorpora Tez in modo che possa tradurre complesse istruzioni SQL in grafici di elaborazione dei dati altamente ottimizzati e appositamente progettati, che raggiungono il giusto equilibrio tra prestazioni, produttività e scalabilità. Le innovazioni di Apache Tez hanno sono alla base di molti dei miglioramenti delle prestazioni di Hive offerti dalla Stinger Initiative, un progetto di una grande comunità, realizzato con il contributo di 145 ingegneri di 44 diverse organizzazioni. Tez contribuisce a rendere Hive interattivo.

Cosa fa Tez
Apache Tez fornisce un'API e un framework per sviluppatori per scrivere applicazioni YARN native, che collegano l'intera gamma dei carichi di lavoro interattivi e in batch. Permette a queste applicazioni di accesso ai dati di elaborare petabyte di dati presenti su migliaia di nodi. La libreria dei componenti di Apache Tez consente agli sviluppatori di creare applicazioni Hadoop che si integrano in modo nativo con Apache Hadoop YARN e con buone prestazioni all'interno di cluster di carichi di lavoro misti. Poiché Tez è estensibile e integrabile, offre tutta la libertà necessaria per esprimere applicazioni di elaborazione dei dati altamente ottimizzate, che risultano pertanto vantaggiose rispetto ai motori per gli utenti finali come MapReduce e Apache Spark. Tez offre anche un'architettura di esecuzione personalizzabile che permette agli utenti di esprimere calcoli complessi come grafici del flusso di dati, consentendo ottimizzazioni dinamiche delle prestazioni basate su informazioni reali relative ai dati e alle risorse necessarie per elaborarli.
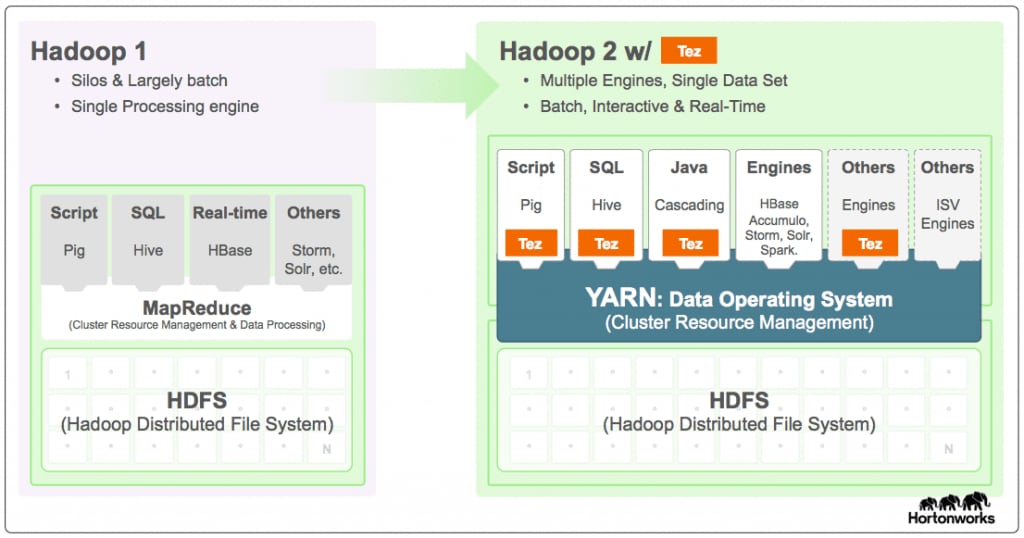
Come funziona Tez
Il miglioramento dell'elaborazione dei dati di Apache Tez all'interno di Hadoop è di gran lunga superiore ai vantaggi dati Apache Hive e Apache Pig. Il progetto ha fissato lo standard per una vera integrazione con YARN per quanto riguarda i carichi di lavoro interattivi. Leggi le seguenti brevi informazioni sul modo in cui Apache Tez porta a termine le attività principali.
Esprimi, modella ed esegui la logica di elaborazione
Tez modella l'elaborazione dei dati nella forma di un grafico del flusso di dati, in cui i vertici del grafico rappresentano la logica dell'applicazione e i bordi rappresentano lo spostamento dei dati. Una completa API di definizione del flusso di dati consente agli utenti di esprimere in modo intuitivo complesse logiche di query. L'API si adatta bene ai piani di query prodotti da applicazioni dichiarative di livello superiore come Apache Hive e Apache Pig.
Interazione di modello tra i moduli di input, del processore e di output
Tez modella la logica utente in esecuzione in ciascun vertice del grafico del flusso di dati come un insieme di moduli di input, del processore e di output. L'input e l'output determinano il formato dei dati nonché le modalità e le posizioni di lettura e scrittura. Il processore è responsabile della logica di trasformazione dei dati. Tez non impone alcun formato di dati e richiede solo che i formati di input, del processore e di output siano compatibili tra loro.
Riconfigura in modo dinamico i grafici
L'elaborazione dei dati distribuiti è dinamica ed è difficile determinare in anticipo i metodi di spostamento dei dati migliori. Ulteriori informazioni diventano disponibili durante il runtime; in questa fase è possibile ottimizzare ulteriormente il piano di esecuzione. Per questo motivo, Tez è compatibile con moduli di gestione dei vertici innestabili che raccolgono informazioni di runtime e modificano in modo dinamico il grafico del flusso di dati, così da ottimizzare le prestazioni e l'utilizzo delle risorse.
Ottimizza le prestazioni e la gestione delle risorse
YARN gestisce le risorse in un cluster Hadoop, in base alla capacità e al carico del cluster. Il framework del motore di esecuzione Tez acquisisce in modo efficiente le risorse da YARN e riutilizza ogni componente della pipeline in modo tale che nessuna operazione venga duplicata inutilmente.
API per la definizione di grafici aciclici diretti (DAG)
Tez definisce una semplice API Java per esprimere un DAG di elaborazione dei dati. L'API ha tre componenti
- DAG: definisce il lavoro nel complesso. L'utente crea un oggetto DAG per ciascun processo di elaborazione dei dati.
- Vertice: definisce la logica utente e l'ambiente e le risorse necessari per eseguirla. L'utente crea un oggetto vertice per ogni passaggio dell'operazione e lo aggiunge al DAG.
- Bordo: definisce la connessione tra i vertici dei componenti produttori e consumatori. L'utente crea un oggetto bordo che serve per collega i vertici dei componenti produttori e consumatori.
Riutilizzo dei container
Tez segue il tradizionale modello Hadoop di suddivisione di un'operazione in singole attività, tutte eseguite come processi tramite YARN per conto degli utenti. Questo modello comporta costi intrinseci per l'avvio e l'inizializzazione del processo, la gestione delle deviazioni e l'allocazione di ciascun container tramite il gestore di risorse di YARN.