Apache Storm
Un sistema per l'elaborazione di dati in streaming in tempo reale
Apache™ Storm aggiunge a Enterprise Hadoop funzionalità di elaborazione dati in tempo reale affidabili. Storm su YARN è ideale per scenari che richiedono analisi in tempo reale, machine learning e monitoraggio continuo delle operazioni.
Storm si integra con YARN tramite Apache Slider; YARN gestisce Storm e contemporaneamente prendere in considerazione le risorse del cluster relative ai componenti di governance, sicurezza e operazioni dei dati di una moderna architettura di dati.

Cosa fa Storm
Storm è un sistema di calcolo distribuito in tempo reale per l'elaborazione di grandi volumi di dati ad alta velocità. Storm è estremamente veloce, con la capacità di elaborare oltre un milione di record al secondo per nodo su un cluster di dimensioni modeste. Le aziende sfruttano questa velocità e la combinano con altre applicazioni di accesso ai dati in Hadoop per prevenire eventi indesiderati o per ottimizzare risultati positivi.
Tra le nuove specifiche opportunità commerciali vi sono: la gestione del servizio clienti in tempo reale, la monetizzazione dei dati, i dashboard operativi e le analisi sulla sicurezza informatica e il rilevamento delle minacce.
Di seguito vengono descritti alcuni utilizzi tipici di Storm per "prevenire" e "ottimizzare".
| "Prevent" Use Cases | "Optimize" Use Cases | |
|---|---|---|
| Financial Services |
|
|
| Telecom |
|
|
| Retail |
|
|
| Manufacturing |
|
|
| Transportation |
|
|
| Web |
|
|
Storm è semplice e gli sviluppatori possono scrivere topologie Storm con qualsiasi linguaggio di programmazione . Cinque caratteristiche rendono Storm ideale per i carichi di lavoro di elaborazione dei dati in tempo reale. Storm è:
- Veloce: dai test risulta essere in grado di elaborare un milione di messaggi da 100 byte al secondo per nodo.
- Scalabile: è in grado di eseguire calcoli paralleli su un cluster di macchine.
- Tollerante agli errori: quando i processi worker vengono interrotti, Storm li riavvia automaticamente. Se un nodo viene interrotto, il processo worker viene riavviato su un altro nodo.
- Affidabile: Storm garantisce che ogni unità di dati (tupla) verrà elaborata almeno una volta o esattamente una volta. I messaggi vengono riprodotto solo in caso di errori.
- Facile da usare: le configurazioni standard sono pronte per la produzione sin dal primo giorno di implementazione. Dopo la distribuzione, Storm è facile da usare.
Come funziona Storm
Un cluster Storm presenta tre gruppi di nodi:
- Nodo Nimbus (nodo principale, simile al JobTracker di Hadoop):
- Carica i calcoli da eseguire
- Distribuisce il codice nel cluster
- Avvia i processi worker nel cluster
- Monitora il calcolo e rialloca i processi worker a seconda delle necessità
- Nodi ZooKeeper: coordinano il cluster Storm
- Nodi supervisore: comunicano con il nodo Nimbus tramite i nodi Zookeeper e avviano e arrestano i processi worker a seconda dei segnali ricevuti dal nodo Nimbus

Cinque astrazioni chiave aiutano a capire in che modo Storm elabora i dati:
- Tuple: un elenco ordinato di elementi. Ad esempio, una tupla di 4 elementi potrebbe essere: (7, 1, 3, 7).
- Stream: una sequenza illimitata di tuple.
- Spout: sorgenti di stream in un calcolo (ad es. un'API di Twitter)
- Bolt: elaborano stream di ingresso e producono stream di uscita. Sono in grado di: eseguire funzioni; filtrare, aggregare o unire i dati; comunicare con i database.
- Topologie: il calcolo complessivo, rappresentato visivamente come una rete di spout e bolt (come nel diagramma in basso)
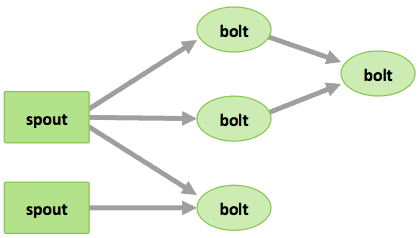
Gli utenti Storm definiscono le topologie su come elaborare i dati quando arrivano in streaming dallo spout. Quando i dati arrivano, vengono elaborati e i risultati vengono passati ad Hadoop.